批流一体大数据分析架构的设计与实现
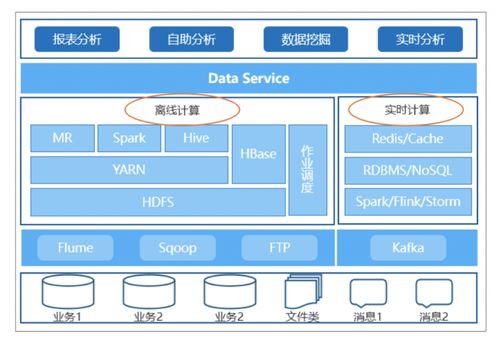
在当今数据驱动的时代,企业对数据处理能力的要求日益提高。批流一体架构能够同时处理实时数据和批量数据,为企业提供快速、准确的数据洞察。本文将介绍批流一体大数据分析架构的搭建流程,重点涵盖数据处理和存储支持服务的设计。
1. 架构概述
批流一体架构融合了批量处理和流式处理的优势,通过统一的数据模型和工具链,实现数据的统一采集、处理与存储。核心思想是构建一个既能处理历史批量数据,又能处理实时数据流的平台,使得数据分析任务能够无缝切换或并行执行。
2. 数据处理层设计
数据处理层是批流一体架构的核心,负责数据的接入、清洗、转换和计算。常见的组件包括:
- 数据接入工具:如Apache Kafka或Pulsar,用于实时数据流接入;Apache Sqoop或Flume可用于批量数据导入。
- 计算引擎:推荐使用Apache Flink或Spark,它们天然支持批流统一处理。Flink以其低延迟和状态管理能力著称,适合复杂的实时计算;Spark则提供强大的批处理能力,并通过Structured Streaming扩展流处理功能。
- 数据处理框架:采用Lambda架构或Kappa架构。Lambda架构结合批处理和流处理层,适合高可靠性场景;Kappa架构则简化设计,仅依赖流处理,通过重播数据实现批处理。
在实施中,需定义统一的数据格式(如Avro或Parquet),确保批流数据的一致性。例如,使用Flink的Table API或Spark的DataFrame API,编写统一的SQL或代码逻辑处理数据。
3. 数据存储层设计
数据存储层需要支持高吞吐、低延迟的读写,并兼容批流数据。常见存储方案包括:
- 实时存储:使用NoSQL数据库如Apache HBase或Cassandra,用于快速查询实时结果;缓存系统如Redis可加速热点数据访问。
- 批量存储:数据湖技术如Apache HDFS或云存储(如AWS S3),用于存储原始批量数据和历史快照。
- 统一存储层:采用数据湖house概念,结合Delta Lake或Apache Iceberg,提供ACID事务和版本控制,实现批流数据的统一管理。这些工具支持在同一个存储系统中处理实时更新和批量数据,简化数据治理。
存储设计时,需考虑数据分区和索引策略,以优化查询性能。例如,按时间分区可加速时间范围查询,同时支持实时流数据的追加和批量数据的覆盖。
4. 支持服务与工具集成
为了确保架构的稳定性和可扩展性,需要集成支持服务:
- 元数据管理:使用Apache Atlas或DataHub,跟踪数据血缘和治理,确保数据质量。
- 调度与编排:工具如Apache Airflow或Dagster,用于协调批处理和流处理任务,实现自动化流水线。
- 监控与告警:集成Prometheus和Grafana,监控数据处理延迟和资源使用情况,及时发现问题。
- 安全与权限:通过Kerberos或Apache Ranger实施访问控制,保护敏感数据。
云平台服务(如AWS Kinesis for streaming和EMR for batch)可以简化部署,提供托管解决方案。
5. 实施步骤与最佳实践
搭建批流一体架构时,建议按以下步骤进行:
- 需求分析:明确业务场景,如实时推荐或历史报表,确定数据处理延迟和准确性要求。
- 组件选型:根据团队技能和基础设施,选择适合的计算引擎和存储系统。从小规模试点开始,逐步扩展。
- 数据建模:设计统一的数据模式,使用事件时间处理来对齐批流数据,避免时间不一致问题。
- 测试与优化:模拟高负载场景,调优资源配置(如并行度和内存分配),并实施数据备份和容错机制。
- 持续迭代:通过监控反馈,不断优化架构,适应业务变化。
批流一体大数据分析架构通过统一的数据处理与存储层,能够高效支撑复杂的数据需求。实施时,注重组件集成和数据一致性,将显著提升企业的数据分析能力。
如若转载,请注明出处:http://www.kjifkj.com/product/13.html
更新时间:2026-06-19 13:25:52