HDFS大规模数据存储底层原理详解 第31天 - 数据处理和存储支持服务
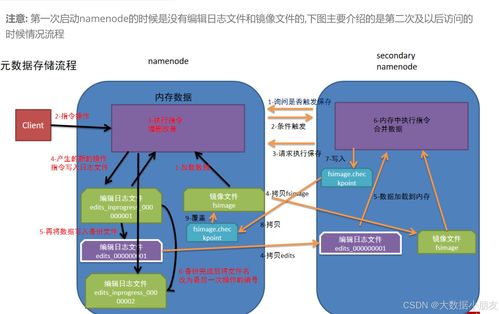
在Hadoop分布式文件系统(HDFS)中,大规模数据的处理和存储依赖于一系列核心服务,这些服务确保了数据的高效、可靠和可扩展性。第31天的主题聚焦于数据处理和存储支持服务,这是HDFS底层原理的关键组成部分。本文将详细解析这些服务的功能、工作原理及其在实际应用中的重要性。
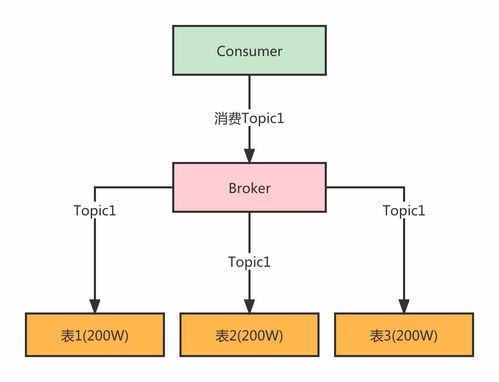
HDFS的数据处理支持服务主要包括数据块管理、副本机制和数据节点通信。数据块管理负责将大文件分割成固定大小的块(默认为128MB),并通过分布式方式存储在多个数据节点上。副本机制通过复制数据块(默认3个副本)到不同的节点,提高了数据的容错性和可用性。数据节点通过心跳协议与名称节点通信,定期报告其状态和块信息,确保系统能够监控和响应节点故障。
存储支持服务涵盖存储策略、数据本地性优化和故障恢复。HDFS支持多种存储策略(如热数据、冷数据存储),允许用户根据访问频率配置数据存储位置。数据本地性优化通过在计算节点(如MapReduce任务)附近存储数据,减少了网络传输开销,提升了处理效率。故障恢复服务包括自动副本重新复制和节点重启机制,当数据节点失效时,系统会自动从健康节点复制数据,保证数据完整性。
HDFS还集成了其他支持服务,如数据压缩、加密和快照功能。数据压缩(例如使用Gzip或Snappy)减少了存储空间和网络带宽消耗;加密服务通过透明数据加密(TDE)保护敏感信息;快照功能允许用户创建文件系统的只读副本,便于数据备份和恢复。这些服务共同构建了一个强大的数据处理和存储生态系统,支持大规模数据应用如日志分析、机器学习等。
HDFS的数据处理和存储支持服务是其核心优势,通过分布式架构和智能管理,确保了大数据环境下的高性能和可靠性。理解这些底层原理,有助于优化系统配置和解决实际生产中的问题。
如若转载,请注明出处:http://www.kjifkj.com/product/24.html
更新时间:2026-06-19 13:25:22