大数据采集工具及数据处理与存储支持服务概览
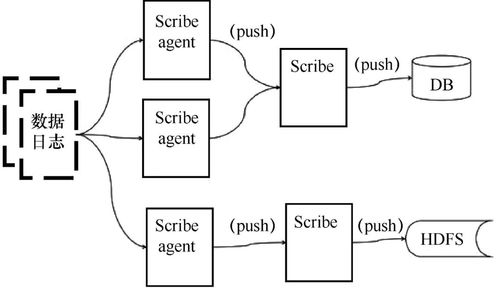
随着大数据技术的快速发展,企业和组织对数据采集、处理和存储的需求日益增长。本文将介绍常见的大数据采集工具,以及数据处理和存储支持服务,帮助读者全面了解相关技术选项。
一、大数据采集工具
大数据采集工具负责从各种来源(如数据库、日志文件、传感器、社交媒体等)收集数据,并将其传输到数据存储或处理系统中。以下是几类常用的大数据采集工具:
1. 日志采集工具:例如 Fluentd 和 Logstash,它们能够从应用程序、服务器等收集日志数据,支持实时传输和过滤。
2. 数据同步工具:如 Apache Sqoop,专用于在 Hadoop 和关系型数据库之间高效传输数据。
3. 流数据采集工具:例如 Apache Kafka,它作为分布式消息队列,支持高吞吐量的实时数据流采集和发布。
4. Web 数据抓取工具:如 Scrapy 和 Apache Nutch,用于从网页中爬取结构化数据。
5. 物联网(IoT)数据采集工具:如 Apache NiFi,提供可视化界面,方便从传感器和设备中采集数据。
这些工具通常支持多种数据格式和协议,并可集成到大数据生态系统中。
二、数据处理支持服务
数据处理服务负责对采集到的数据进行清洗、转换、分析和计算,以提取有价值的信息。主要服务包括:
1. 批处理服务:例如 Apache Hadoop 的 MapReduce 和 Apache Spark,适用于大规模离线数据处理。
2. 流处理服务:如 Apache Flink 和 Apache Storm,支持实时数据处理和复杂事件处理。
3. 数据仓库服务:例如 Amazon Redshift 和 Google BigQuery,提供快速查询和分析结构化数据的能力。
4. 数据湖服务:如 AWS Lake Formation 和 Azure Data Lake,允许存储和处理各种原始数据格式,支持机器学习和分析工作负载。
这些服务通常提供可扩展的计算资源、内置算法和用户友好界面,帮助用户高效处理数据。
三、数据存储支持服务
数据存储服务负责持久化存储大数据,确保数据的安全性、可靠性和可访问性。常见服务包括:
1. 分布式文件系统:例如 Hadoop HDFS,适合存储大规模非结构化数据。
2. NoSQL 数据库:如 MongoDB、Cassandra 和 HBase,用于存储半结构化或非结构化数据,支持高并发访问。
3. 云存储服务:例如 Amazon S3、Google Cloud Storage 和 Azure Blob Storage,提供弹性、高可用的对象存储方案。
4. 时序数据库:如 InfluxDB,专为处理时间序列数据(如监控数据)设计。
5. 内存数据库:如 Redis,适用于需要快速读写的场景。
这些存储服务通常集成备份、加密和访问控制功能,以满足不同业务需求。
四、集成与最佳实践
在实际应用中,大数据采集、处理和存储服务往往需要集成使用。例如,可以使用 Apache Kafka 采集实时数据,通过 Apache Spark 进行流处理,然后将结果存储到 Amazon S3 或 HBase 中。最佳实践包括:
- 根据数据量、实时性和成本选择合适工具和服务。
- 采用数据治理策略,确保数据质量和合规性。
- 利用云平台(如 AWS、Azure 或 Google Cloud)的托管服务,简化运维。
大数据生态系统提供了丰富的采集、处理和存储工具与服务。通过合理选择和组合,企业和组织能够构建高效、可扩展的数据流水线,支持数据驱动的决策和创新。
如若转载,请注明出处:http://www.kjifkj.com/product/2.html
更新时间:2026-06-19 13:51:46