千万流量大型分布式系统架构设计实战 数据处理与存储支持服务的核心要义
在当今互联网时代,支撑千万级甚至亿级日活跃用户(DAU)的系统已成为众多企业的核心基础设施。构建这样一个高并发、高可用的分布式系统,其架构设计尤为关键,而数据处理与存储支持服务更是整个系统的基石与生命线。本文将从实战角度,深入剖析千万流量大型分布式系统架构中,数据处理与存储支持服务的设计理念、核心组件与最佳实践。
一、架构设计核心挑战与目标
面对千万级流量,系统架构设计首要解决的是海量数据、高并发访问、低延迟响应以及高可用性四大挑战。数据处理与存储服务的设计目标因此明确为:
- 高扩展性(Scalability):能够通过水平扩容(如增加节点)平滑应对数据量和访问量的指数级增长。
- 高可用性(Availability):确保服务7x24小时不间断运行,任何单点故障不影响整体服务。
- 高性能(Performance):在毫秒级内完成数据的读写操作,满足用户体验要求。
- 数据一致性(Consistency):在分布式环境下,根据业务场景在强一致、最终一致等模型间做出合理权衡。
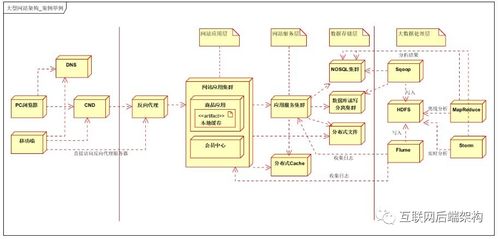
二、数据处理与存储服务分层架构
一个稳健的大型系统通常采用分层、分治的设计思想。数据处理与存储支持服务可抽象为以下三层:
1. 接入与缓存层
这是抵御洪峰流量的第一道防线。
- 负载均衡:采用LVS、Nginx或云服务商提供的SLB,将流量均匀分发至后端服务集群。
- 分布式缓存:核心组件如Redis Cluster或Memcached,用于缓存热点数据(如用户会话、热门内容),将请求拦截在数据库之外,降低数据库压力。关键策略包括缓存预热、多级缓存架构及缓存失效/更新策略(如Cache-Aside、Write-Through)。
2. 计算与消息中间件层
负责数据的异步处理、解耦和流量削峰。
- 消息队列:Kafka、RocketMQ、Pulsar等是异步化的核心。它们承载日志收集、订单处理、事件驱动等场景,通过削峰填谷提升系统整体吞吐量和韧性。
- 流式计算平台:对于实时数据处理需求(如实时监控、风控),Flink、Spark Streaming等组件能够进行低延迟的流式分析和计算。
3. 持久化存储层
数据的最终归宿,根据数据结构与访问模式进行选型。
- 关系型数据库:MySQL、PostgreSQL。处理强一致性要求的核心事务数据。实践中普遍采用分库分表(如ShardingSphere、Vitess)来突破单库性能瓶颈,并通过主从复制、读写分离提升读能力和可用性。
- NoSQL数据库:
- KV存储:如Redis(持久化)、etcd(配置),用于特定高速访问场景。
- 文档型:MongoDB,适合存储半结构化、模式易变的数据。
- 列式存储:HBase、Cassandra,擅长海量数据的随机读写与范围查询,常用于大数据平台。
- 时序数据库:InfluxDB、TDengine,专为监控指标、物联网传感器数据优化。
- 对象存储:如Amazon S3、阿里云OSS,用于存储图片、视频、日志文件等海量非结构化数据,具备近乎无限的扩展能力。
- 大数据存储:HDFS、Iceberg、Hudi,用于数据湖、离线分析等场景。
三、核心实战策略与“干货”
1. 数据库分库分表实战
- 分片键选择:至关重要,应选择查询频繁、数据分布均匀的字段(如用户ID),避免跨分片查询。
- 平滑扩容:设计之初需考虑未来扩容方案,可采用一致性哈希等算法减少数据迁移量。
- 全局ID生成:摒弃数据库自增ID,采用雪花算法(Snowflake)、UUID或分布式ID服务(如Leaf)来保证全局唯一性。
2. 缓存穿透、击穿、雪崩应对
- 穿透:查询不存在的数据。解决方案:布隆过滤器(Bloom Filter)快速判定是否存在,或缓存空值(设置短过期时间)。
- 击穿:热点Key过期瞬间大量请求直达数据库。解决方案:互斥锁(分布式锁)保证仅一个线程回源重建缓存,或设置逻辑过期时间(永不过期,后台异步更新)。
- 雪崩:大量Key同时过期。解决方案:给缓存过期时间添加随机值,避免集体失效;或建立高可用的缓存集群(如Redis Sentinel/Cluster)。
3. 读写分离与数据同步
- 利用数据库原生复制或中间件(如Canal、Maxwell)监听binlog,将数据变更近乎实时地同步到读库或缓存。
- 应用层通过中间件(如MyCat、ShardingSphere)或配置多个数据源来透明化地实现读写分离。
4. 数据一致性保障
- 最终一致性主流:大部分互联网场景可接受短期不一致。通过消息队列确保缓存与数据库、数据库与数据库间的异步同步。
- 分布式事务:对于强一致性要求的核心交易,可采用TCC、Saga、本地消息表等柔性事务方案,或借助Seata等中间件。
5. 监控与治理
- 全方位监控:对数据库连接数、QPS、慢查询、缓存命中率、消息队列堆积等进行实时监控(Prometheus + Grafana)。
- 容量规划与弹性伸缩:基于监控指标进行预测,并利用云平台或Kubernetes实现存储与计算资源的自动弹性伸缩。
四、
设计千万流量级别的数据处理与存储架构,没有银弹,只有权衡。关键在于深刻理解业务数据模型与访问模式,灵活组合缓存、消息队列、各类数据库等组件,构建一个层次清晰、职责分明、可弹性扩展的技术栈。必须将监控、告警、容灾、数据备份与恢复等运维能力融入架构设计的每一个环节。通过持续的性能压测、故障演练和架构迭代,才能锻造出真正坚实可靠的数据基石,从容应对流量洪峰与业务增长的挑战。
如若转载,请注明出处:http://www.kjifkj.com/product/36.html
更新时间:2026-06-19 22:30:28